
Applying Data Science to Data Science
The spirit of MLC@Home is building tools and running analyses to understand machine learning models. The first project launched under MLC@Home is the Machine Learning Dataset Generator (MLDS). MLDS aims to build (and make public!) a massive dataset of thousands of neural networks trained on similar, highly controlled data. By doing so, we can turn the lens inward, and apply some of the same data science techniques we already to build these models to understand of the models.
To our knowledge these are among the first and the largest datasets of their kind.
Datasets
MLDS is taking a phased approach to generating a dataset, starting with a simple "Dataset 1" (DS1), and adding more datasets with increased complexity going forward. Each dataset download contains a README file describing that's included and technical details of the training. When using these datasets please cite: MLDS: A Dataset for Weight-Space Analysis of Neural Networks.
These datasets are made available under a CC BY-SA 4.0 license.MLDS-DS1: RNNs Mimicing Simple Machines
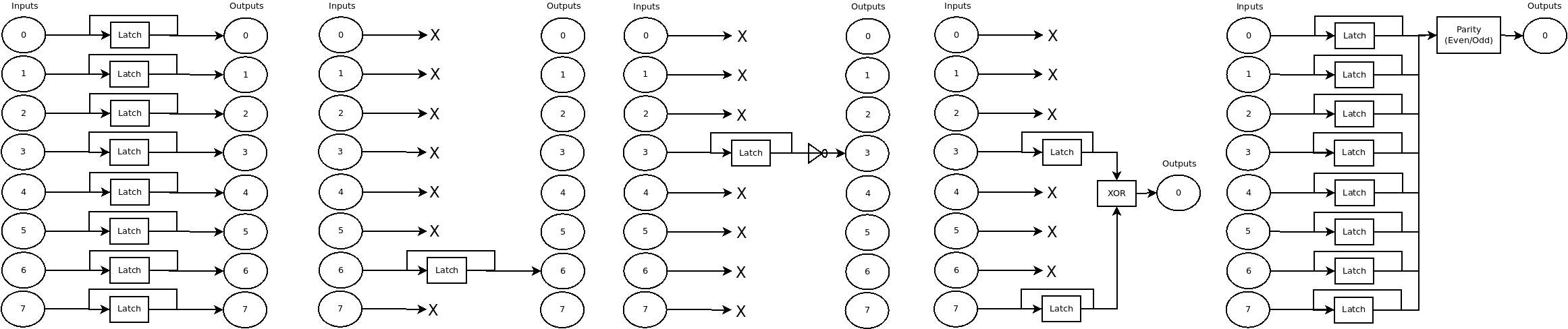
This dataset contains up to 50,000 neural networks trained to mimic one of 5 simple machines detailed in the paper "Learning Device Models with Recurrent Neural Networks" (arXiv:1805.07869). These simple RNN networks use 4 GRU layers followed by 4 linear layers (4,364 parameters) to translate a series of input commands into a series of outputs. They range from trivially learnable within a few epochs, to difficult to learn even with thousands of epochs. They are small and easy to train even on a CPU, so they make a good test case for the MLC@Home infrastructure.
The networks all have the same shape, only the weights differ. MLC@Home is training 10,000 examples of each network type. The download links below contain links to the full dataset, or optionally smaller subsets of the full 10,000 networks.
| Status | MLDS-DS1-100 | MLDS-DS1-500 | MLDS-DS1-1000 | MLDS-DS1-5000 | MLDS-DS1-10000 |
|---|---|---|---|---|---|
| Computation | Complete | Complete | Complete | Complete | Complete |
| Download | v1.0 67MB [ tar.gz | md5 ] |
v1.0 206MB [ tar.gz | md5 ] |
v1.0 383MB [ tar.gz | md5 ] |
v1.0 1.8GB [ tar.gz | md5 ] |
v1.0 3.5GB [ tar.gz | md5 ] |
MLDS-DS2: RNNs Mimicing Simple Machines with a Magic Sequence
MLDS-DS2 consists of the nearly identical machines to MLDS-DS1, with one important distinction. The machines have been modified in such a way that if the input contains a specific 3-command sequence, the output of the network will be inverted for the following 3 output commands. Thus, the machines in DS2 are almost identical to, but fundamentally different from the machines in MLDS-DS1. Thus, DS2 can be paired with DS1 to study how similar networks trained on similar-but-not-identical data behave.
| Status | MLDS-DS2-100 | MLDS-DS2-500 | MLDS-DS2-1000 | MLDS-DS2-5000 | MLDS-DS2-10000 |
|---|---|---|---|---|---|
| Computation | Complete | Complete | Complete | Complete | Complete |
| Download | v1.0 66MB [ tar.gz | md5 ] |
v1.0 206MB [ tar.gz | md5 ] |
v1.0 386MB [ tar.gz | md5 ] |
v1.0 1.8GB [ tar.gz | md5 ] |
v1.0 3.5GB [ tar.gz | md5 ] |
MLDS-DS3: RNNs Mimicing Randomly-Generated Automata
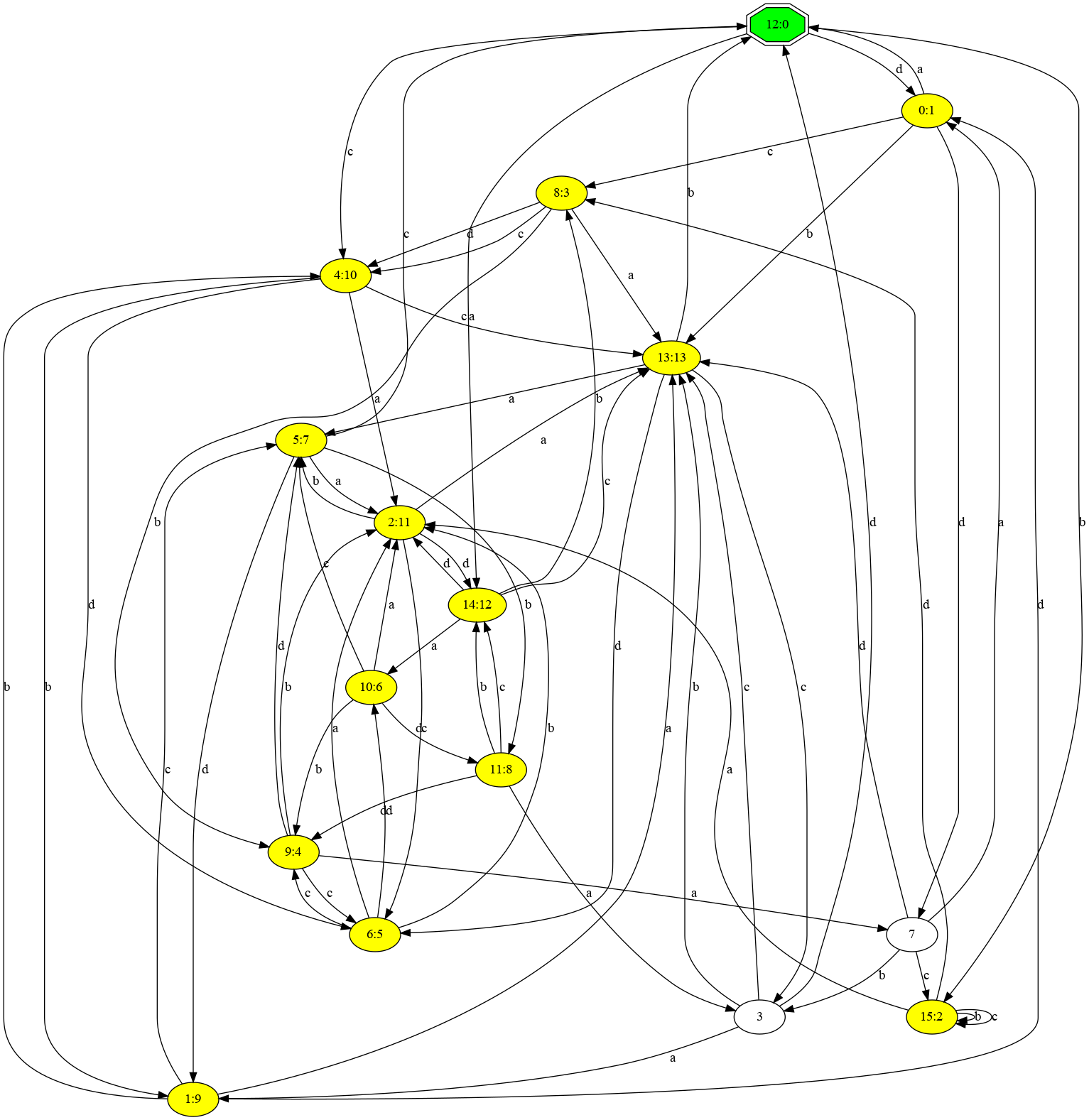
MLDS-DS3 steps away from the five machines used in DS1 and DS2, and instead learns to mimic the behavior of randomly generated automata. These automata all share some common rules: There is at least one hamiltonian cycle, every input is valid even if it doesn't change state, and not every internal state transition is reflected in the output (aka, there are some hidden states). An example of such an automaton is shown above.
MLDS-DS3 is also generating networks for a larger number of different automata. Instead of five machines, DS3 trains networks on 100 different automata. These automata are much more complex, thus the resulting networks are 64-wide, 4 layer deep LSTMs followed by 2 linear layers, or 136846 parameters.
| Status | MLDS-DS3-100 | MLDS-DS3-500 | MLDS-DS3-1000 | MLDS-DS3-5000 | MLDS-DS3-10000 |
|---|---|---|---|---|---|
| Computation | Complete | Complete | Complete | Complete | Complete |
| Download | v1.0 13GB [ torrent | md5 ] |
v1.0 63GB [ torrent | md5 ] |
v1.0 126GB [ torrent | md5 ] |
v1.0 631GB [ torrent | md5 ] |
v1.0 1.3TB [ torrent | md5 ] |
MLDS-DS4: CNNs, Image Classification, and TrojAI
MLDS-DS4 is currently in development, and will expand beyond the RNNs/sequence modelling in the first 3 datasets, and instead focus on simple image classification. In these cases, we will train networks on both standard training data, and modified training data from the TrojAI project. This way we hope to show if the insigts gained from our RNN data is applicable to the CNN domain and image classification.
Other Information
MLDS is not the only task envisioned for MLC@Home. We expect to leverage it for neural architecture search, hyperparameter search, and repoducibility research as well in the near future.